Nous avons vu en introduction de cette unité que pour établir une connexion, notre ordinateur est connecté à une box, elle-même connectée au réseau de votre fournisseur, qui lui-même est connecté à un routeur du réseau.
Le routeur est lui-même relié à d’autres routeurs, chacun collaborant pour trouver la meilleure route possible pour faire transiter les messages réseaux.
Selon les stratégies de routage, cette route peut changer d’une requête à l’autre en fonction de l’encombrement du réseau ou être fixe tant que l’on n’a pas mis fin à la communication.
Mais au-delà de ces concepts, les connexions réelles mettent en jeu d’autres notions telles que celles du serveur mandataire et du certificat.
Dans cette unité, nous allons découvrir ensemble l’envers du décor d’une connexion web.
¶ Fonctionnement basique d'une connexion web
¶ RÉSOLUTION DNS
Pour commencer cette unité revoyons ensemble quelques grands principes sur le fonctionnement basique d’une connexion web.
Lorsque vous tapez l’adresse www.ssi.gouv.fr dans votre navigateur par exemple, la première étape consiste à obtenir l’adresse IP à laquelle le nom de domaine (www.ssi.gouv.fr) est associé.
On appelle cette étape la résolution DNS.
Le DNS (Domain Name System) est le nom d’un service hiérarchique distribué jouant le rôle d’annuaire pour Internet.
Les noms de domaines sont ainsi découpés en domaines et en sous-domaines, qui sont gérés par différentes entités.
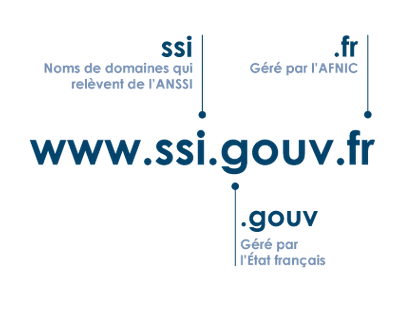
Nous l’avons vu dans l’unité 3 de ce module, pour le cas particulier de la recherche www.ssi.gouv.fr, il faut lire le nom de domaine de la droite vers la gauche.
Tout d’abord, commençons par la racine, qui n’est pas visible dans le nom de domaine présenté, et qui est gérée sous l’autorité de l’ICANN (Internet Corporation for Assigned Names and Numbers).
Ensuite, le domaine fr (ainsi que le domaine gouv.fr) sont gérés par une association en France : l’Afnic (Association Française pour le Nommage Internet en Coopération).
Enfin, le domaine ssi.gouv.fr est sous l’autorité de l’ANSSI, qui est donc responsable de donner l’adresse IP concernant le service www.ssi.gouv.fr.
En théorie, à chaque requête web il faut donc consulter ces différents acteurs (ICANN, Afnic) pour obtenir l’adresse IP correspondant au service recherché.
Pour rendre la chose plus efficace, on utilise un service appelé « DNS cache » qui pose les questions DNS et en retient les réponses pour un usage futur.
Ce service est mis à disposition par les fournisseurs d’accès à internet.
Le nom de serveur « DNS cache » vient du terme « mémoire cache », que l’on peut traduire en français par « antémémoire ».
Il s’agit d’un mécanisme classique qui consiste à enregistrer temporairement des données pour accélérer les requêtes ultérieures.
On retrouve également ce concept au niveau matériel (mémoire cache des processeurs ou des disques durs).
¶ REQUÊTE HTTP
Lorsque l’adresse IP est obtenue, le navigateur peut envoyer une requête HTTP (HyperText Transport Protocol) à destination du serveur pour obtenir le contenu de la page web.
Ce protocole a vu le jour au CERN à la fin des années 80.
Le protocole HTTP était dès l’origine étroitement lié au langage HTML (HyperText Markup Language), le format des pages web.
¶ ET ENSUITE ?
En pratique, lorsqu’un document HTML est téléchargé, celui-ci fait référence à de nombreuses ressources.
Il peut s’agir de feuilles de style (pour décrire comment afficher la page), d’images à inclure dans le document, ou encore de scripts permettant par exemple de calculer des statistiques sur l’utilisation de la page.
Certaines pages web incluent également des liens vers les réseaux sociaux ou des espaces publicitaires, qui sont autant de ressources à télécharger et à intégrer dans la page à afficher.
Toutes ces ressources doivent à leur tour être récupérées via le protocole HTTP.
Lorsque le navigateur a obtenu la page web, ainsi que tous les éléments qu’elle contient, le navigateur présente le résultat à l’utilisateur.
Dans certains cas, l’affichage d’une page web peut correspondre à des dizaines (voire des centaines) de requêtes HTTP !
¶ Utilisation d'un serveur mandataire
¶ PRINCIPES
Comme pour la résolution DNS, la récupération systématique de l’ensemble des ressources d’une page web à chaque connexion peut se révéler gourmande en bande passante.
Or, certains éléments (par exemple les images ou les feuilles de style) ne changent pas d’une connexion à l’autre.
Il est donc inutile de les télécharger à chaque fois !
Le serveur mandataire es un serveur Proxy.
¶ SERVEUR MANDATAIRE ET SÉCURITÉ
En plus d’apporter un gain important sur les performances, un serveur mandataire peut avoir un intérêt pour la sécurité.
En effet, en tant que point de passage obligé pour les requêtes HTTP, le serveur mandataire est un endroit idéal pour journaliser les requêtes effectuées par les utilisateurs d’une entité.
Un tel journal peut se révéler essentiel pour retrouver a posteriori les traces d’une attaque informatique.
Par exemple, si un rançongiciel donné déclenche le téléchargement d’une ressource par ses victimes, l’analyse des journaux permet rapidement d’identifier les machines compromises !
Au-delà de l’analyse a posteriori, le serveur mandataire peut également servir à bloquer l’accès à des ressources malveillantes connues.
En reprenant l’exemple du rançongiciel précédent, si le serveur web utilisé pour télécharger le logiciel malveillant est connu a priori, il est possible d’ajouter des règles dans le serveur mandataire pour bloquer de telles requêtes, et ainsi empêcher en amont l’infection des postes clients.
¶ HTTPS et les certificats
Lorsque l’on considère des connexions HTTP classiques, celles-ci consistent en des messages « en clair » sur internet.
Cela signifie que tous les équipements réseau entre le client et le serveur peuvent voir le contenu de la requête et de la réponse.
Ces équipements peuvent même modifier ces contenus !
Cette situation pose évidemment des problèmes de sécurité.
¶ HTTPS ET LE CADENAS
Historiquement, quand Internet puis le Web sont apparus, il n'était pas question de cybercriminalité.
S'échanger un message à travers le monde était une révolution.
Le chiffrement était une arme de guerre et l'utiliser pour rendre le message « Bienvenue sur ma page » illisible sur le réseau semblait inutile, voire ridicule.
Désormais ce sont votre adresse, votre numéro de sécurité sociale, votre numéro de carte bleue qui s'échangent sur ce réseau mondial.
Ces données intéressent forcément des personnes malveillantes qui n’ont qu'à attendre paisiblement depuis leur ordinateur que vous les transmettiez en clair sur le réseau pour les récupérer et s'en servir ou les revendre.
Pour éviter que vos données soient facilement interceptées, les cryptographes ont créé le protocole SSL puis TLS comme nous l’avons abordé dans le module 2 de ce MOOC.
On a vu ainsi le « S » de « Sécurisé » s'ajouter au protocole HTTP pour devenir HTTPS.
Le préfixe HTTPS dans la barre d'adresses (ou sa représentation graphique avec un cadenas qui tend à disparaître) est la garantie que votre ordinateur échange des données de manière sécurisée avec le serveur distant du site Web, c'est-à-dire que potentiellement personne entre vous et le site Web ne peut lire les données échangées.
Notez qu’une tendance actuelle sur l’affichage dans les navigateurs est de présenter une connexion HTTP comme non sécurisée (HTTP barré en travers et en rouge), plutôt que de mettre en avant l’aspect sécurisé d’une connexion HTTPS.
¶ PRINCIPE DE FONCTIONNEMENT HTTPS
Afin de protéger les connexions HTTPS en confidentialité et en intégrité (c’est-à-dire pour éviter qu’un attaquant puisse lire le contenu, ou le modifier), on utilise la cryptographie, qui a été abordée en fin de module 2.
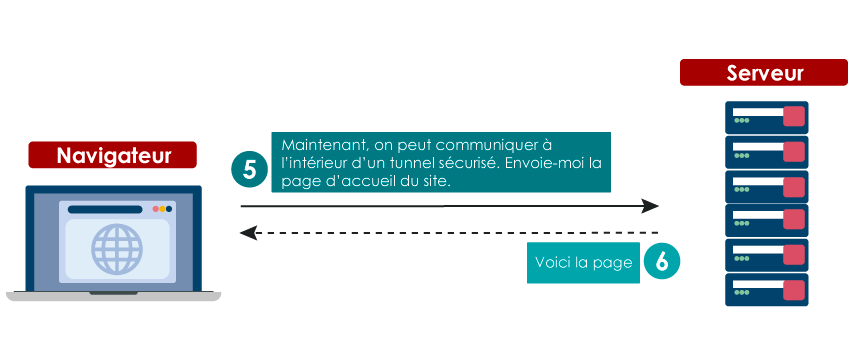
Pour cela, une connexion HTTPS repose sur deux phases :
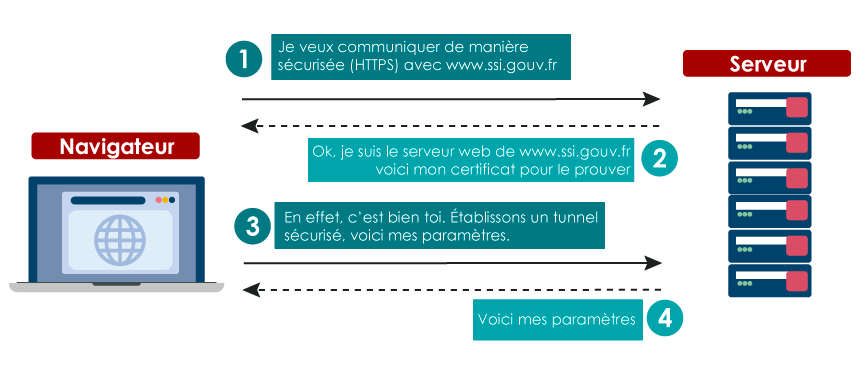
¶ LE CERTIFICAT D’UN SERVEUR HTTPS
Lors de la première phase, le serveur présente un certificat électronique.
Celui-ci contient trois éléments essentiels :
- L’identité du serveur que le client souhaite visiter.
- Une clé publique associée au serveur.
- La signature d’une autorité de certification, qui lie les deux informations précédentes et qui garantit leur intégrité.
À la réception d’un tel certificat, le navigateur doit s’assurer que la signature est valide (ce qui garantit l’intégrité du contenu) et correspond bien à une autorité de certification qu’il reconnaît.
Il doit aussi vérifier que l’identité présentée est bien celle qu’il attendait.
Lorsque ces vérifications sont réalisées, le navigateur peut alors sereinement utiliser la clé publique contenue dans le certificat pour communiquer avec le serveur.
Il est alors possible d’utiliser la cryptographie asymétrique pour échanger une clé symétrique entre le client et le serveur.
C’est une application de la technique du chiffrement hybride décrite dans l’unité 5 du module 2.